



Blog//
8 Pillars That Make Data Ready for AI
July 11, 2026
July 6, 2026

The currency of the new economy is trust, but the raw material is data." — Satya Nadella
Data is both the fuel for AI programs and one of their greatest liabilities.
Well-prepared data drives effective AI training and model development. Data that hasn't been properly readied leads to wasted investment, unreliable decisions, missed opportunities, and regulatory exposure.
Gartner reports that 63% of organizations either lack or are uncertain whether they have the right data readiness practices for AI. The same research predicts that through 2026, organizations will walk away from 60% of AI projects that aren't supported by AI-ready data.
Organizations need a repeatable framework for transforming data into a state that AI systems can work with reliably.
What the research says about AI-ready data
Since 2016, the FAIR principles (Findable, Accessible, Interoperable, Reusable) have served as the global benchmark for data management. They were not designed with modern AI systems in mind. FAIR describes how to organize and share information. AI requires proof that the underlying data is appropriate, legally permissible, traceable, safe to learn from, and governed across the full model lifecycle.
Several extensions have emerged to close that gap:
FAIR-R adds a "Readiness" dimension, emphasizing data quality for AI, bias detection, lineage tracking, and performance benchmarking as prerequisites for responsible model development.
AIDRIN (AI Data Readiness Inspector) introduces a quantitative layer. It pairs traditional quality checks like completeness, duplicate detection, and consistency with AI-specific metrics: class imbalance, feature correlations, fairness, and privacy scoring.
The ODI Framework takes a broader view, evaluating dataset properties, metadata, and supporting infrastructure across quality, representativeness, timeliness, and ethical dimensions to confirm that data pipelines are transparent and trustworthy.
Despite these contributions, no single universal definition for AI-ready data exists. Requirements differ by domain, risk profile, and the intended behavior of the model.
What "AI-ready data" means in practice
Without a consensus definition, organizations tend to treat AI data readiness as a practical discipline rather than a fixed standard. In operational terms, AI-ready data means preparing data to serve the requirements of a specific AI system. Traditional preprocessing is part of that work, but insufficient on its own.
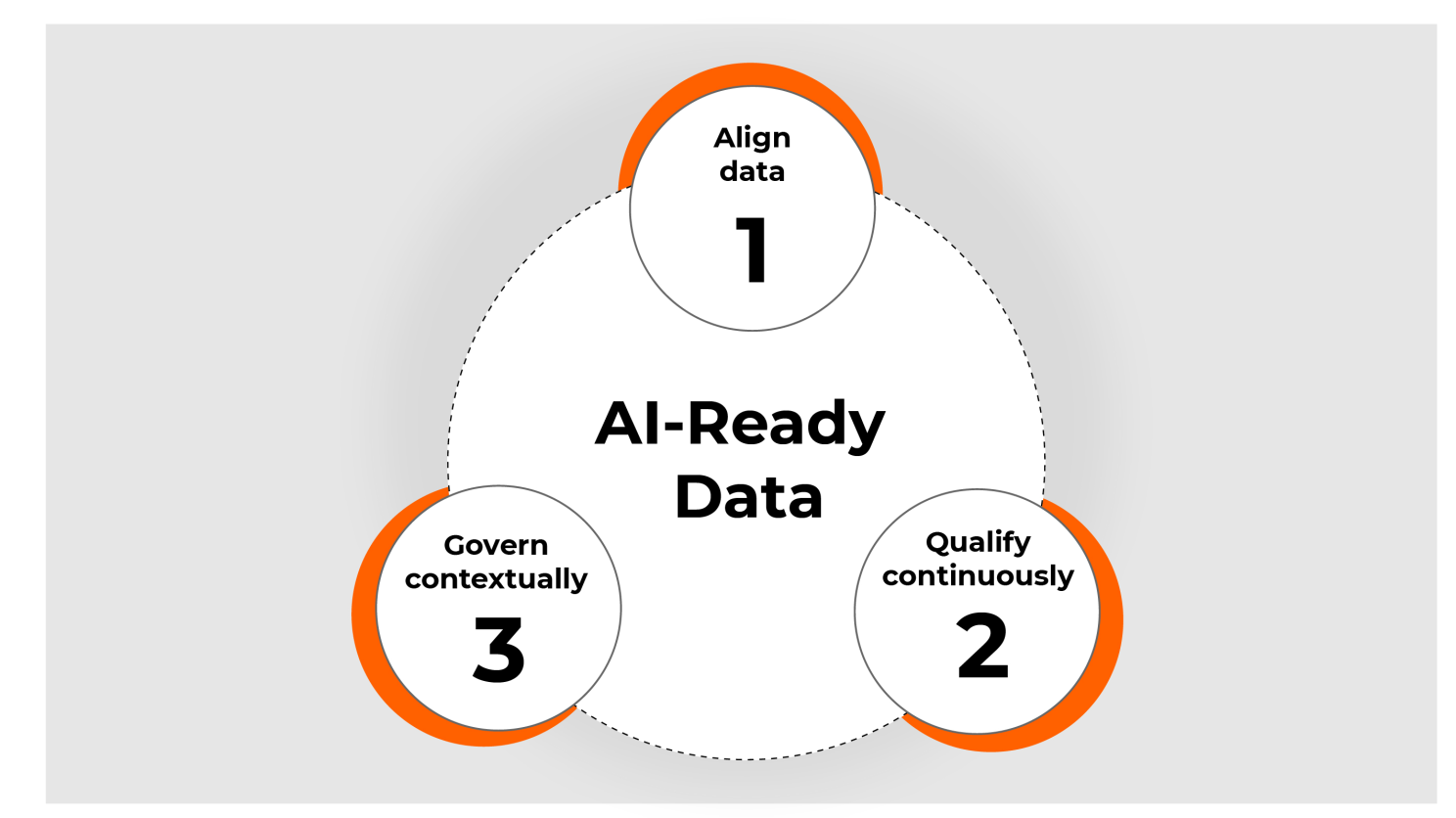
A useful way to put AI readiness into practice is through three connected actions:
- Aligning data by imposing consistent structure and maintaining reliable metadata across sources.
- Qualifying data by validating completeness, versioning, and traceability, with checks tied directly to model objectives.
- Governing data by managing access controls, security, fairness, and oversight, forming the foundation of sound enterprise data governance.
The 8 pillars of AI-ready data
Drawing on insights from FAIR-R, AIDRIN, and ODI research, we have identified eight pillars that define what AI-ready data looks like in practice.
Structure
Standardize IT data into a consistent, machine-readable format. This is a foundational step in any data pipeline modernization effort. For instance, converting web server logs into a uniform JSON schema where fields like timestamp, log_level, and hostname follow the same conventions across every source simplifies integration, reduces transformation errors, and accelerates downstream analysis.
Accessibility
Eliminate data silos so that IT operations can be understood through a single, unified view. This is essential for building dependable observability pipelines. Engineers troubleshooting an incident should not have to query separate systems for application logs, Kubernetes events, and database metrics. Consolidating these sources under a central data lakehouse or observability platform puts critical data within reach when it matters most.
Versioning
Capture dataset snapshots at defined intervals to protect AI model reliability. When a model predicting server failures begins to degrade, teams need to determine quickly whether changes in the underlying data caused the regression. Versioned datasets make that diagnosis possible, shortening troubleshooting cycles and maintaining confidence in model outputs.
Traceability
Maintain a clear, unbroken chain of data lineage from origin to consumption. In a security investigation, for example, teams should be able to follow a single request_id from the firewall log through the web server, authentication service, and application layer, preserving full visibility and accountability at every step.
Metadata
Metadata serves as the operating manual for a dataset. It gives analysts the context they need to determine whether data is trustworthy and how it should be used. A dataset of network packet captures carries little value without details about its source, schema, collection time zone and frequency, and any known quality issues. Thorough metadata management makes all of that context explicit and accessible.
Security
Build security into AI-ready data from the start. Production logs frequently contain sensitive information: email addresses, session tokens, IP addresses. Automating PII detection and masking prevents sensitive data from reaching central analytics platforms and turning them into unintended repositories of regulated information. This also lowers downstream risk for AI and analytics workflows by reducing the likelihood of privacy violations, legal exposure, and accidental PII leakage in models or dashboards.
Fairness
Confirm that AI models perform reliably across all conditions by using data bias detection to identify skewed distributions before they enter training pipelines. An anomaly detection model trained exclusively on US business-hour traffic may misclassify legitimate activity from other regions or time zones. Analyzing and rebalancing data distributions ensures that AI sees a representative picture and produces accurate results regardless of context.
Completeness
Ensure that data records are thorough enough to support analytics, anomaly detection, and MLOps requirements. In real IT operations, a missing user-session trace or a gap in a critical time span can make root cause analysis or anomaly detection impossible. Validating, flagging, and enriching records produces more complete, reliable datasets that are ready for AI consumption.
Key takeaway
Poorly prepared data can undermine an entire AI program. The 8-pillar framework provides a structured path for converting messy, fragmented data into the high-quality input that intelligent systems require. It also helps teams reclaim time currently spent on data preparation, which can consume up to 80% of project effort, and redirect that time toward work that drives innovation.
How Astreya puts the 8 pillars into practice
Most data tools offer a one-time cleanup.
Our solution on Databricks provides a continuous picture. You see what lives in your systems and how it behaves, where it might create problems for your AI initiatives, and what steps to take to prevent those problems. Pairing Data Pulse with Astreya's IT data catalog sharpens that picture further.
This ongoing visibility changes how teams operate. Rather than chasing pipeline failures or guessing why models behave unpredictably, teams can prepare LLM workloads with confidence, build metadata practices that hold up over time, and address fragile data paths before they become emergencies. The result is a data foundation you can trust rather than one you have to work around.
Interested in learning more? Have a chat with our data and AI-readiness experts.
